메모리
메모리(Memory)란 컴퓨터에서 정보를 처리하기 위해 일시적으로 정보를 보관하는 기억장치를 말합니다.
좁은 의미로 메모리는 주 기억장치인 램(RAM)을 의미하지만,
넓은 의미로는 보조기억장치인 롬(ROM)을 포함하기도 합니다.
램(RAM)과 롬(ROM)의 차이
| 이름 | RAM(Random Access Memory) | ROM(Read Only Memory) |
| 특징 | 전원이 끊기면 기록된 정보가 휘발되는 휘발성 메모리 |
읽기만 하고 쓰지는 못하는 비휘발성 메모리 |
| 종류 | DRAM(DDR3, DDR4), SRAM, SDRAM, DDR SDRAM |
HDD, SDD(SATA SSD, M.2 NVMESSD), CD-ROM, USB |
| 예 |  삼성 DDR4 -3200 (별명 : 삼성 시금치 3200) |
 SK 하이닉스 P.41 SSD |
컴퓨터는 기본적으로 CPU와 ROM만 존재하는 경우 동작이 가능하지만,

그림에서와 같이 CPU와 ROM만 존재할 경우
CPU는 속도가 빨라 작업을 빨리 처리하겠지만, 느린 ROM에서만 데이터를
가져올 수 밖에 없어, 성능이 크게 저하됩니다.
이러한 문제를 해결하기 위해 CPU와 ROM 사이 RAM을 추가하여
CPU가 매우 빠르게 데이터를 읽고 쓸 수 있도록 해줍니다.
메모리의 주소 공간
초기 컴퓨터는 Single Programming
방식을 사용 했습니다.
그래서, 아래 그림과 같이

매우 단순한 형태로 메모리 공간을 사용했습니다.
0 ~ 64KB까지는 운영체제의 공간으로 활용 됐고,
64 ~ 나머지 공간은 현재 프로그램(코드, 데이터 등)이 존재했습니다.
멀티 프로그래밍
시스템 내 여러 프로세스가 실행 가능한 상태가 되면서,
더 이상 위와 같은 단순한 메모리 형태를 사용할 수 없게 됐습니다.

그래서 위와 같이 물리적 메모리를 프로세스 끼리 공유하여 사용했습니다.
하지만, 위와 같이 메모리 공간에 여러 프로세스가 함께 작업을 할 경우
한 프로세스가 작업 중인 내용이 다른 프로세스의 작업 공간을 침범하는 문제가
발생하기 시작 했습니다.
ex) 프로세스C (128KB ~ 192KB)인데 작업 용량이
커져서 프로세스B(192KB ~ 256KB) 까지 넘어가는 문제
=> 보호(Protection)의 문제
이러한 문제를 해결하기 위해 하나의 프로세스가
하나의 메모리 전체를 사용하 듯 착각하게 만드는
"가상 주소 공간"이 생깁니다.
가상 주소 공간
(사용 이유 : 프로세스의 메모리 용량이 다른 프로세스의 작업 공간에 침범하지 않게 하기 위해 사용)


가상 주소 공간은 프로세스가 할당 받은 물리적 주소 공간을 하나의 메모리 공간으로 인식시켜
프로세스가 하나의 메모리 공간 안에서만 작업을 할 수 있게 만들어 줍니다.
만약, 해당 가상 메모리 공간을 다 썼다는 가정하에서는 남는 빈 공간으로 점프해
다시 하나의 가상 메모리를 부여 받고 작업하는 방식으로 발전하게 됩니다.
하지만, 위와 같이 물리 메모리를 64KB 씩 나눠 하나의 프로세스가 차지하고,
가상 메모리 공간의 16KB를 제공할 경우 힙과 스택 영역에 데이터가 없을 경우
낭비되는 공간이 발생하게 됩니다.
add) Code, Data, Heap, Stack
| Code, Data, Heap, Stack 설명 | |
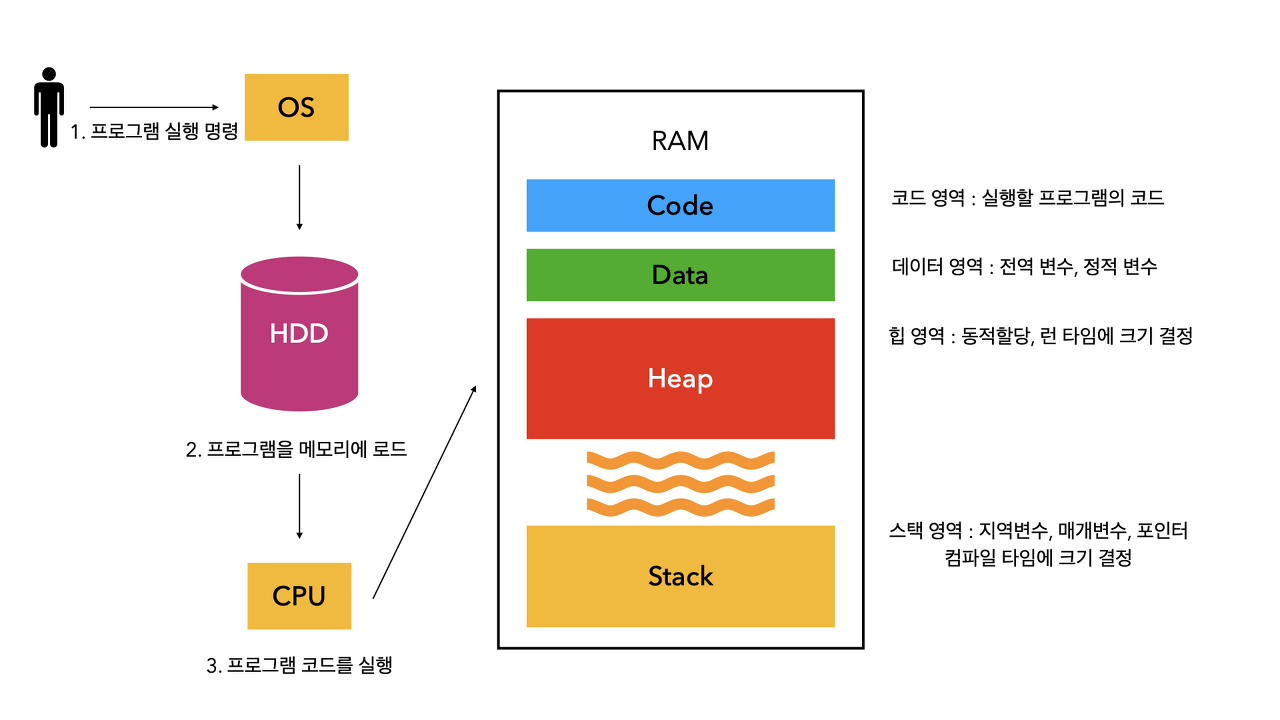 |
|
| Code | 실행할 프로그램의 코드 |
| Data | 전역 변수, 정적 변수 |
| Heap | 동적할당(포인터(*)), 런 타임에 크기 결정 |
| Stack | 지역 변수, 매개변수, 포인터 컴파일 타임에 크기 결정 |
그래서, Code, Data, Heap, Stack의 크기 만큼 유동적으로 메모리에
적재하는 Segement(조각)을 사용하게 됩니다.
Segment(조각)
(사용 이유 : 가상 공간을 일정한 사이즈로 제공할 경우 Stack과 Heap이 사용되지 않으면 낭비되는 공간이 많아진다. 유동적?으로 최소한의 필요한 공간만 제공하는 방식인 Segment 사용)

위의 그림에서 처럼 Base는 시작 위치를 의미하고,
Size는 Code, Heap, Stack의 사이즈를 의미 합니다.
그리고 Stack은 아래에서 위로 쌓이고, Heap은 위에서 아래로
쌓이기 때문에, Grows Positive로 방향을 표시해줍니다.
(offset을 이용한 물리주소 찾는 방법은 생략하겠습니다...)
(지금도 기억을 더듬는 중 입니다...)
하지만, 위와 같이 Segement 조각들로 구성할 경우
잦은 할당과 회수를 반복하면, 메모리 작은 메모리 공간이
중간중간에 생기는 문제가 발생하게 됩니다.
이렇게 중간중간에 생긴 사용하지 않는 메모리는 사용할 수 없고,
이게 누적되면 총 메모리 공간은 충분하지만 실제로 할당할 수 없는
(메모리 낭비)

=> "외부 단편화 문제"가 발생하게 됩니다.
이러한 문제를 해결하기 위해, Paging 방식이 도입 되게 됩니다.
Paging
(사용이유 : Segement의 외부 단편화로 인한 낭비되는 공간을 없애기 위해 사용)
페이징은 메모리를 고정된 크기의 블록으로 나누는 방식으로,
메모리를 관리할 때 각 페이지의 크기는 동일하므로,
크기와 위치가 다른 세그먼트로 인한 단편화 문제를 방지할 수 있습니다.

하지만, Paging 방식은 내부 단편화(내부 공간에서 사용하지 않는 공간 문제)가 존재 합니다.
틀린 부분이 있다면 댓글 창 부탁 드립니다...
최대한 기억을 더듬어가며 정리해봤습니다... 감사합니다...
'컴퓨터 사이언스' 카테고리의 다른 글
| 문맥 교환(Context Switching) (0) | 2024.11.03 |
|---|---|
| 프로세스와 스레드 (0) | 2024.11.03 |
| CPU란? (0) | 2024.10.06 |